Cours : Allocation mémoire
1 Allocation de la mémoire centrale et multiprogrammation.
1.1 Présentation du problème
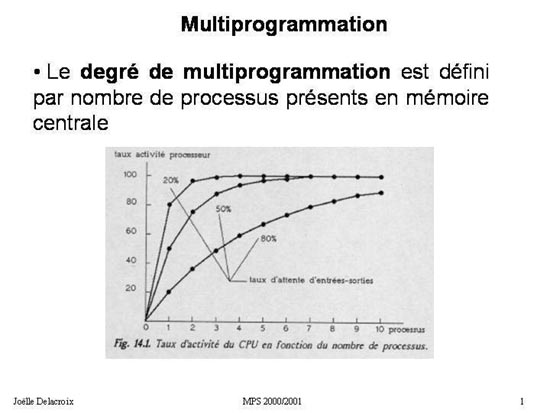
Définition : Degré de multiprogrammation
on définit le degré de multiprogrammation comme étant le nombre de processus présents en mémoire centrale.
Le schéma ci-dessous représente le taux d'activité du processeur en fonction du nombre de processus présents en mémoire centrale
et en fonction du temps d'entrée-sortie de ces processus.
 |
|
|
Fig 1 : Degré de multiprogrammation
|
|
|
|
- Il faut définir un espace d'adressage indépendant pour chaque processus
- Il faut protéger les espaces d'adressage des processus les uns vis-à-vis des autres
- Il faut allouer de la mémoire physique à chaque espace d'adressage.
1.2 Différentes méthodes d'allocation mémoire
- pour la première famille, un programme est un ensemble de mots contigus insécable. L'espace d'adressage du processus est linéaire. On trouve ici les méthodes d'allocations en partitions variables que nous allons étudier en premier.
- pour la seconde famille, un programme est un ensemble de mots contigus sécable, c'est-à-dire que le programme peut être divisé en plus petits morceaux, chaque morceau étant lui-même un ensemble de mots contigus. Chaque morceau peut alors être alloué de manière indépendante. On trouve ici les mécanismes de segmentation et de pagination..
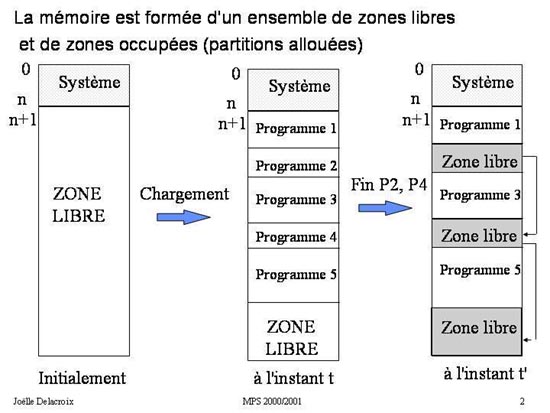
2 Allocation mémoire d'un seul tenant.
 |
|
|
Fig 2 : Allocation en partitions variables
|
|
|
|
 |
|
|
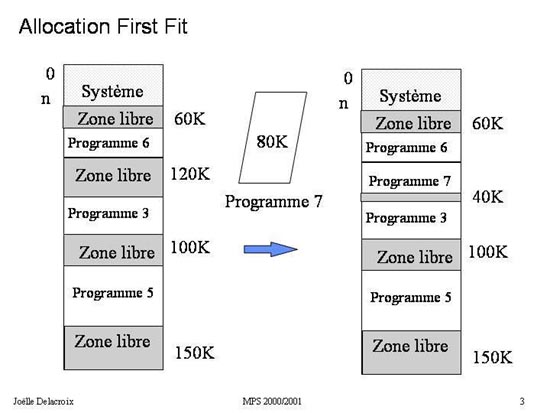
Fig 3 : Stratégie First Fit
|
|
|
|
 |
|
|
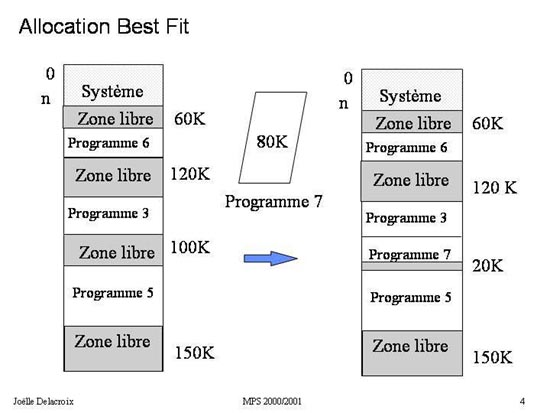
Fig 4 : Stratégie Best Fit
|
|
|
|
Au fur et à mesure des opérations d'allocations et de désallocations, la mémoire centrale devient composée d'un ensemble de
zones occupées et de zones libres éparpillées dans toute l'étendue de la mémoire centrale. Ces zones libres peuvent devenir
trop petites pour permettre l'allocation de nouveaux programmes (problème de
fragmentation
de la mémoire). Par exemple, sur la figure 5, la mémoire centrale com
port
e 3 zones libres mais aucune d'elles n'est assez grande pour contenir un programme 8 de 180K. Pourtant l'ensemble des 3 zones
libres forme un espace de 120 + 20 + 150 = 350K suffisant pour le programme 8. Pour permettre l'allocation du programme 8,
il faut donc réunir l'ensemble des zones libres pour ne former plus qu'une zone libre suffisante : c'est l'opération de
compactage de la mémoire centrale
.
 |
|
|
Fig 5 : Fragmentation et compactage de la mémoire centrale
|
|
|
|
Définition : Fragmentation
Allocations et désallocations successives des programmes en mémoire centrale créent des trous, c'est-à-dire des zones libres
de taille insuffisante en mémoire centrale : la mémoire centrale est alors fragmentée.
Définition : Compactage de la mémoire centrale
Le compactage de la mémoire centrale consiste à déplacer les programmes en mémoire centrale de manière à ne créer qu'une seule
et unique zone libre.
- Elle nécessite une opération de compactage de la mémoire qui est une opération très coûteuse
- Elle exige d'allouer le programme en une zone d'un seul tenant.
Une solution est de diviser le programme en portions de taille fixe et égales à l'unité d'allocation de la mémoire centrale.
On dit alors que le programme est découpé en pages. Le mécanisme d'allocation associé s'appelle la pagination.
3 La pagination
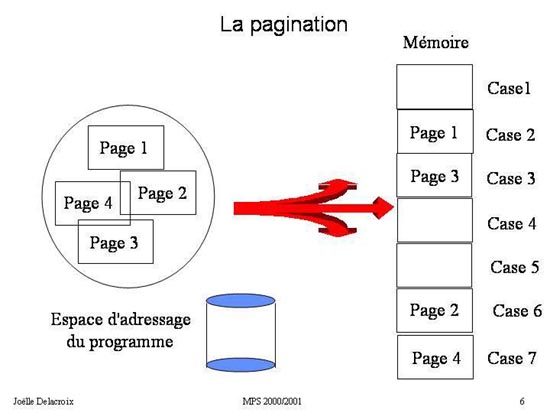
3.1 Principe
Dans le mécanisme de pagination, l'espace d'adressage du programme est découpé en morceaux linéaires de même de taille : la
page.
L'espace de la mémoire physique est lui-même découpé en morceaux linéaires de même taille : la case.
La taille d'une case est égale à la taille d'une page. Dans ce contexte, charger un programme en mémoire centrale consiste
à placer les pages dans n'importe quelle case disponible.
 |
|
|
Fig 6 : Principe de la pagination
|
|
|
|
3.2 Traduction de l'adresse paginée vers l'adresse physique.
Les octets dans la mémoire physique eux ne peuvent être adressés au niveau matériel que par leur adresse physique. Pour toute
opération concernant la mémoire, il faut donc convertir l'adresse paginée générée au niveau du processeur en une adresse physique
équivalente. L'adresse physique d'un octet s'obtient à partir de son adresse virtuelle en remplaçant le numéro de page de
l'adresse virtuelle par l'adresse physique d'implantation de la case contenant la page et en ajoutant à cette adresse physique
d'implantation le déplacement de l'octet dans la page. C'est la MMU (Memory Management Unit) qui est chargée de faire cette
conversion. Il faut donc savoir pour toute page, dans quelle case de la mémoire centrale celle-ci a été placée : cette correspondance
s'effectue grâce à une structure particulière appelée la table de pages.
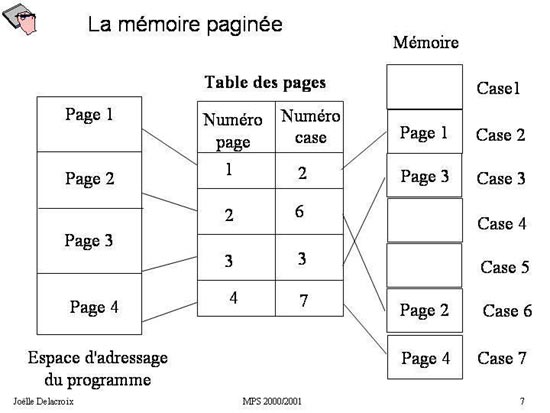
Dans une première approche, la table des pages est une table contenant autant d'entrées que de pages dans l'espace d'adressage
d'un processus. Chaque processus a sa propre table des pages. Chaque entrée de la table est un couple < n°de page, n°de case
physique dans laquelle la page est chargée >. Dans l'exemple de la figure ci-dessous, le processus a 4 pages dans son espace
d'adressage, donc la
table des pages
a 4 entrées. Chaque entrée établit l'équivalence n°de page, n°de case relativement au schéma de la mémoire centrale.
Définition : Table des pages
La table des pages est une table contenant autant d'entrées que de pages dans l'espace d'adressage d'un processus. Chaque
processus a sa propre table des pages. Chaque entrée de la table est un couple < n°de page, n°de case physique dans laquelle
la page est chargée >.
 |
|
|
Fig 7 : Table des pages
|
|
|
|
- à l'aide de registres du processeur : la table des pages est sauvegardée avec le contexte processeur dans le PCB du processus.
- placer les tables des pages en mémoire centrale : la table active est repérée par un registre spécial du processeur le PTBR. Chaque processus sauvegarde dans son PCB la valeur de PTBR correspondant à sa table.
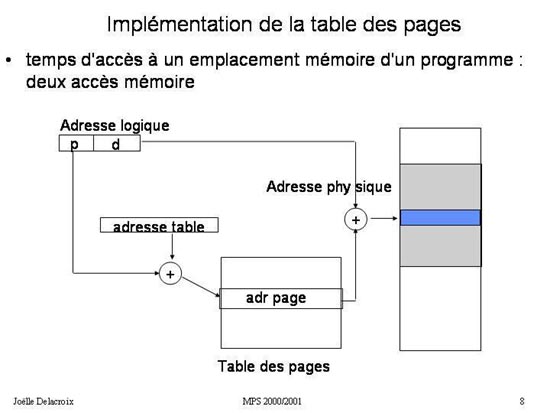
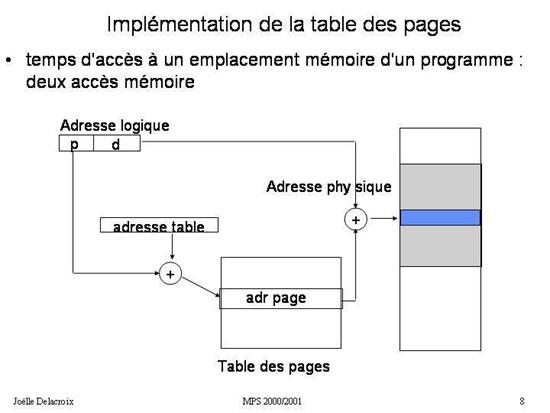
Dans la première approche accéder à un emplacement mémoire nécessite seulement un accès à la mémoire : celui nécessaire à
la lecture ou l'écriture de l'octet recherché puisque la table des pages est stockée dans des registres du processeur. Dans
la deuxième approche accéder à un emplacement mémoire à partir d'une adresse paginée <p,d> nécessite au contraire deux accès
à la mémoire :
- un premier accès permet de lire l'entrée de la table des pages correspondant à la page cherchée : c'est l'opération (p + adresse table) qui délivre une adresse physique de page dans la mémoire centrale.
- un second accès est nécessaire à la lecture ou l'écriture de l'octet recherché à l'adresse <adresse physique > + d.
 |
|
|
Fig 8 : Traduction d'une adresse paginée en adresse physique
|
|
|
|
 |
|
|
Fig 9 : Traduction d'une adresse paginée en adresse physique avec ajout d'un cache associatif
|
|
|
|
4 La segmentation
4.1 Principe
4.2 Traduction de l'adresse segmentée vers l'adresse physique.
 |
|
|
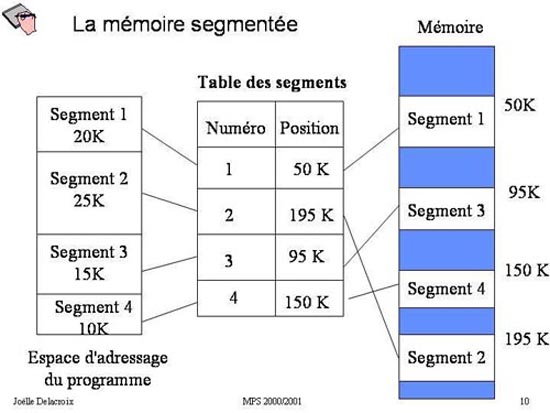
Fig 10 : Table des segments
|
|
|
|
Définition : Table des segments
La table des segments est une table contenant autant d'entrées que de segments dans l'espace d'adressage d'un processus. Chaque
entrée de la table est un couple < n°de segment, adresse d'implantation du segment >.
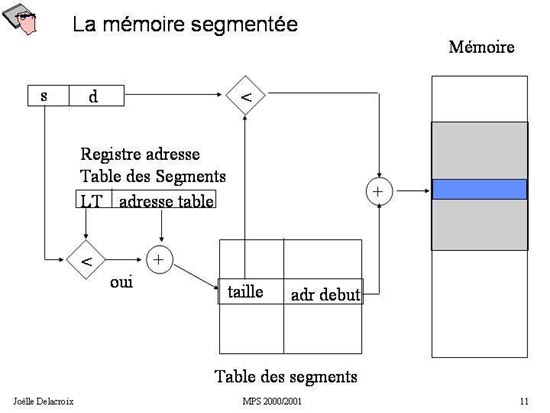
- s est comparé à LT. Si s >= à LT alors il y a erreur : le segment adressé n'existe pas.
- sinon s est additionné à l'adresse de la table des segments de manière à indexer l'entrée de la table concernant le segment s. On récupère alors l'adresse d'implantation du segment s en mémoire centrale (adr début)
- Une information sur la taille du segment peut être conservée dans la table : d est alors comparé à cette information. Si d est supérieure à l'information taille, alors une erreur est générée car le déplacement est en dehors du segment. Sinon , le déplacement d est ajouté à l'adresse d'implantation du segment pour générer l'adresse physique.
 |
|
|
Fig 11 : Traduction d'une adresse segmentée en adresse physique
|
|
|
|
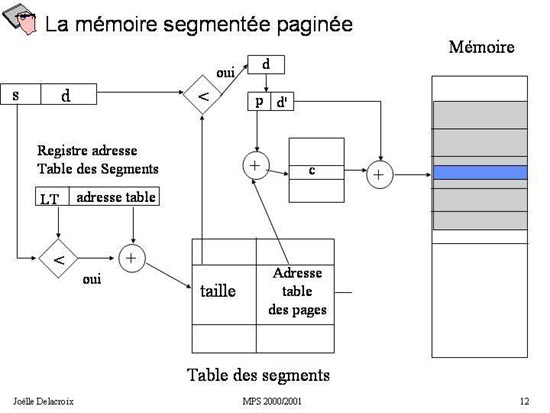
5 Segmentation et Pagination
 |
|
|
Fig 12 : Traduction d'une adresse segmentée et paginée en adresse physique
|
|
|
|